How?
Joint Video-Action Optimization -- learns a unified latent space for both video and action generation.
Decoupled Video-Action Decoding -- speeds up policy inference by skipping video generation.
Masked Training -- enables a single model to handle diverse tasks while reducing overfitting.
Policy Results
Real-world Multi-task
For fair comparisons between methods, all training data are from public datasets and no additional data are used. All evaluation experiments are out-of-distribution.
All evaluations are unseen during training, including unseen environments, objects, backgrounds, and robot grippers.
We compare UVA with the state-of-the-art policy model, Diffusion Policy with a pretrained vision encoder released by UMI (DP-UMI). UVA outperforms DP-UMI in multi-task settings.
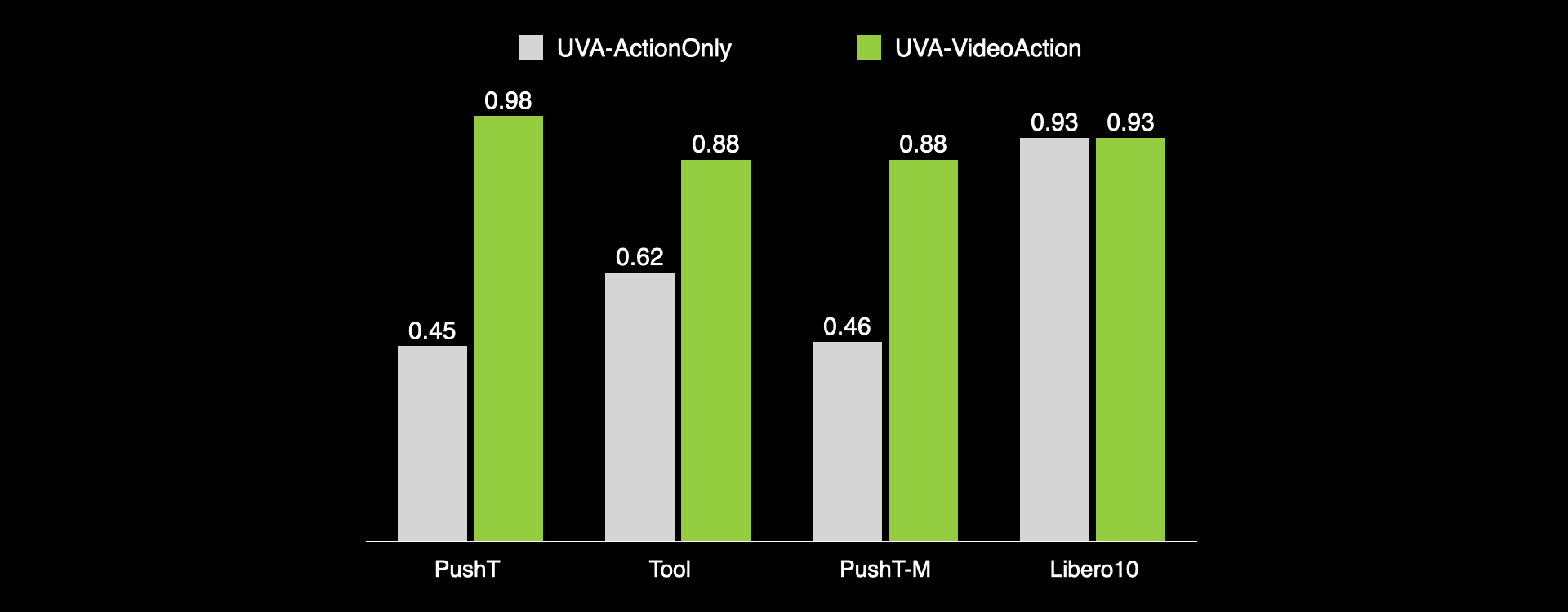
How Much Can Video Generation Boost Policy Learning?
Using video generation as an additional supervision during training can significantly boost policy inference performance, without slowing down policy inference speed.
Video Generation Results
Results on validation set. UVA generates high-quality videos that closely match the ground truth. In contrast, UniPi occasionally produces blurry or mismatched images and may fail to generate some objects (Libero10: the second moka pot). In our experiments, we predict 4 future video frames. However, the UVA framework can also be extended for longer video predictions with more compute resources.
Forward Dynamics Results
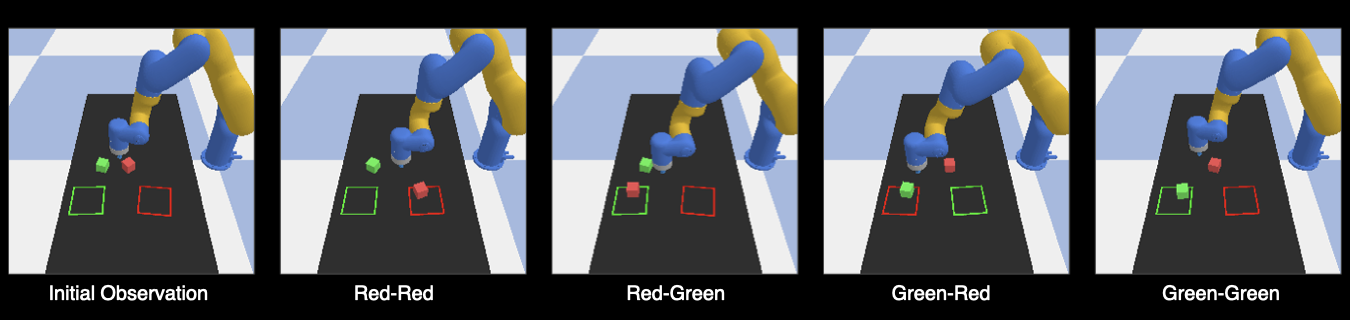
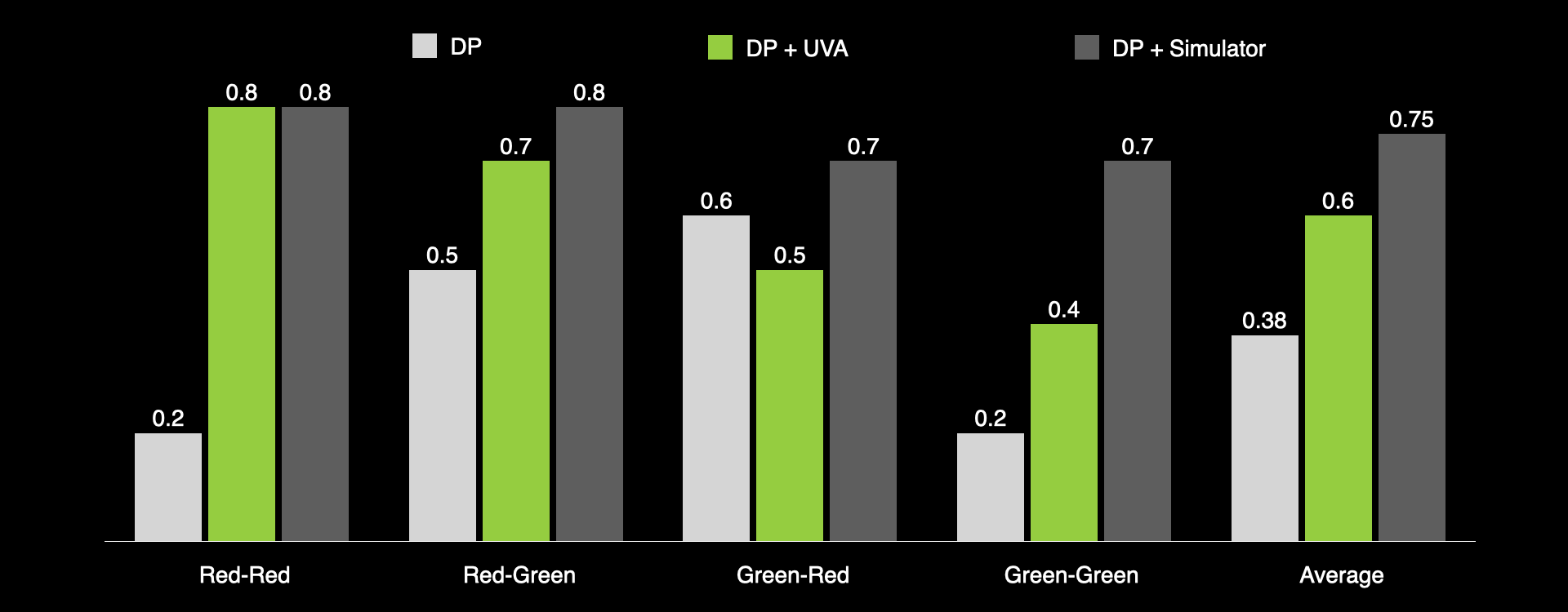
Our model can perform forward dynamics predictions to generate future observations based on action inputs. We use it to predict future observations to guide the behavior of a pretrained policy model, such as the Diffusion Policy (DP). During training, the robot pushes two blocks randomly to any target. During testing, the generated future image from UVA is used to select the proper action that moves a specific object to a specific target.
DP alone achieves an 38% average success rate, while incorporating our model to generate future observations for trajectory selection increases the success rate to 60%. Using a ground-truth simulator provides an upper bound success rate of 75%.
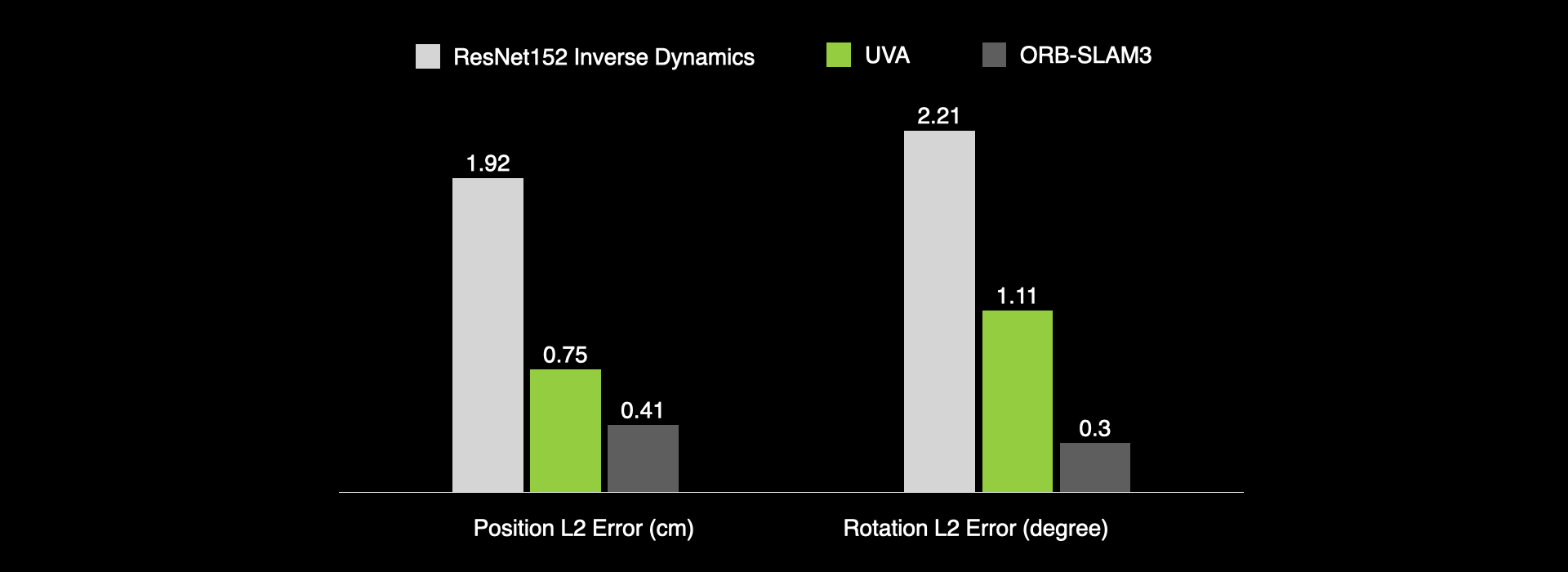
Inverse Dynamics Results
Our model can be used for inverse dynamics predictions on unseen data. Given observations, UVA can predict the actions that cause the visual changes. ORB-SLAM3 is a well-engineered SLAM system used in UMI. While SLAM achieves the best accuracy, it requires careful calibration and map-building.
Model Architecture
Failure Cases
During testing, when we introduced combined, never-before-seen tasks, the model sometimes got confused about what to do and slipped into "task-generalization" mode in an unexpected way, such as put mouse on saucer and put cup on towel. We believe that incorporating more diverse language inputs and better integrating language with the current framework could help—something for us to explore in future work.
Questions & Answers
Are there any tips for training UVA?
We found that two-stage training works better than training on both video and action tasks simultaneously. In the first stage, the model is trained on video generation, and in the second stage, it is fine-tuned on both video and action tasks.
How long does it take to train UVA?
Training time depends on both the size of the dataset and the complexity of the task. For the UMI task, we sampled 500 trajectories from each of the three datasets and trained the model using 8 H100 GPUs. The video generation task was trained for 2 days, while the joint video and action generation requires an additional 2 days.
What's the next step for UVA?
We believe there is still significant potential in UVA that remains unexplored, and we leave this for future work.
Additional video data: UVA can leverage large amounts of actionless video data, which could provide valuable additional supervision. We plan to pretrain UVA on additional video data in the future.
Multi-modality: UVA can be naturally extended to predict modalities beyond video and action, such as sound and force, by incorporating additional diffusion heads, offering a more comprehensive and versatile framework.
Better architecture: The model architecture can be futuer improved by replacing the diffusion heads with flow matching.
Larger model size: UVA's performance may currently be limited by the model size. We plan to explore larger models in the future.
Acknowledgement
The authors would like to thank Huy Ha for his valuable advice on video recording and website design. We also thank Amber Xie, Austin Patel, Jennifer Grannen, Vincent de Bakker, John So, Max Du, and Vidhi Jain for their important feedbacks on the paper draft. We are grateful to Mengda Xu, Suneel Belkhale, Xiaomeng Xu, Fanqi Lin, Lirui Wang, and Tianhong Li for helpful discussions. We would like to express our gratitude to Chi Cheng, Zhenjia Xu, Chuer Pan, Zeyi Liu, Huy Ha, Fanqi Lin, Yingdong Hu, and Zhaxizhuoma for their contributions to the shared UMI dataset. Finally, we want to thank everyone who contributed their computing resources to help us train the models.
This work was supported in part by the Toyota Research Institute, NSF Award #1941722, #2143601, #2037101, #2132519, ONR Project #N00014-22-1-2293 and the DARPA TIMAT project. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.



